
🤖 AI Search and Q&A for Your Dev.to Content with Vrite
No one can deny that ChatGPT brought Large Language Models (LLMs) into the public spotlight. While LLMs are not perfect, when you think about it, the ability to ask a wide variety of questions and get an answer in seconds is mind-blowing. 🤯
The only thing left is to somehow connect it with your own data and provide a new context for the LLM to source answers from. This is where text embeddings, vector databases, and semantic search come in. However, depending on your use case, implementing the entire stack necessary to power an “AI search” or a Question-and-Answer (Q&A) type of interface might be quite a challenge… but it doesn’t have to be.
With the latest update, Vrite — an open-source technical content management platform I’m working on — now has a built-in search and a Q&A feature to find answers to all the questions related to your content. Both inside Vrite — via a new command palette — and outside — via an API. ✨
This can be used to easily build a new kind of search experience for your blog or to provide answers to user’s questions in your product docs.
To give you a fun example of that, we’ll go through a process of importing content from the Dev.to API to Vrite to search through it, and then see how you can easily implement a semantic search on your own site using Vrite APIs.
Setting-up
Let’s start by getting into Vrite. You can use the hosted version (free while Vrite is in Beta) or self-host Vrite from the source code (with better self-hosting support coming soon)
To import your Dev.to content collection to Vrite, it’d be best to do so in a dedicated workspace. In Vrite, you can use workspaces to separate different projects or teams. To create a new one, from the sidebar go to the Workspace section.
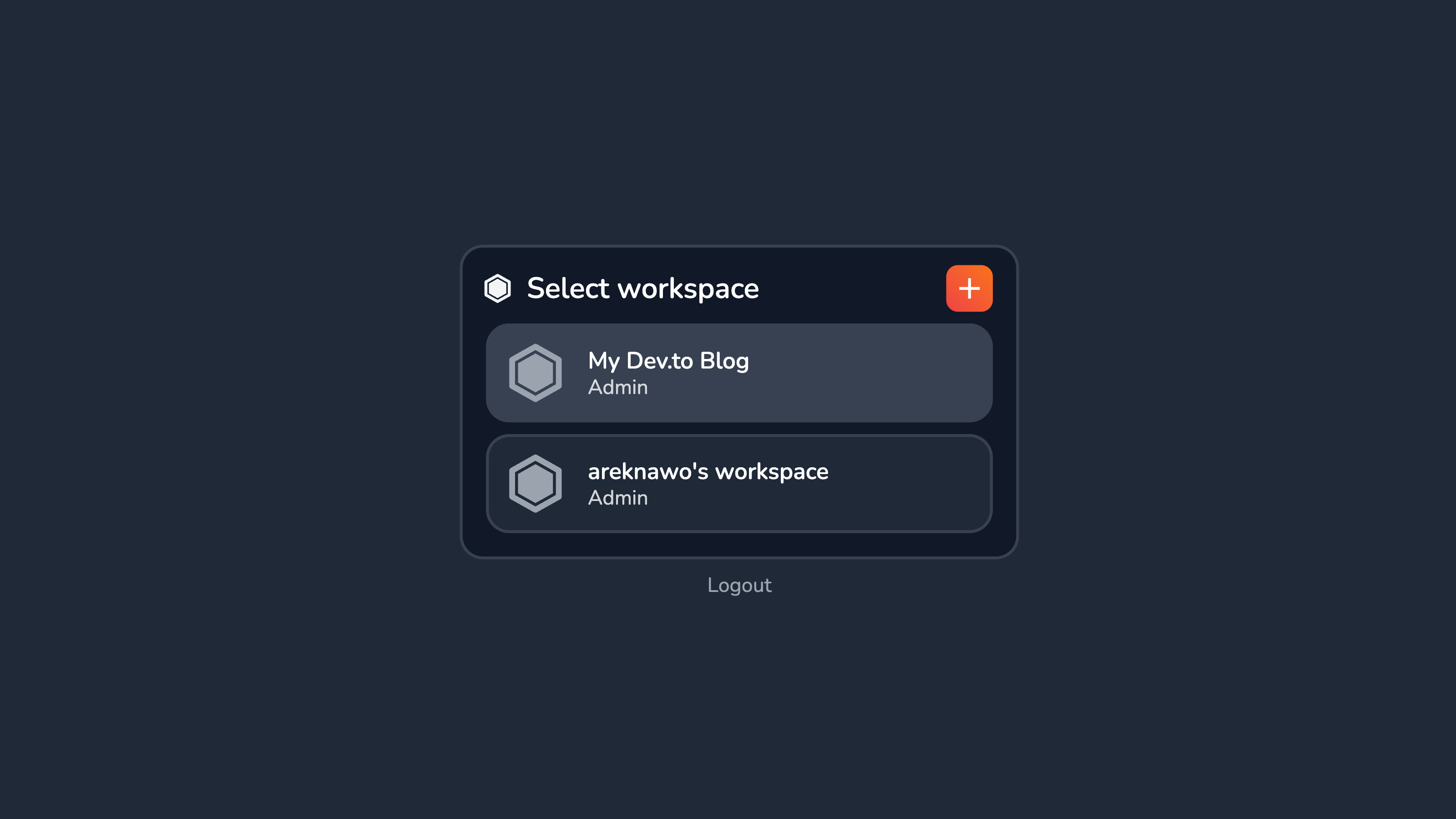
From here, you can both create and switch between different Workspaces. Create one for your Dev.to blog and switch to it.
With the dedicated workspace ready, you’ll have to create a new API token — both in Vrite and Dev.to — to use in the import script.
To get one in Vrite, go to the Settings side panel → API section → click New API token. From here you’ll have to configure the details and permissions for the new token. Make sure to select Write permission for both Content pieces and Content groups, as these will be necessary to import the content.
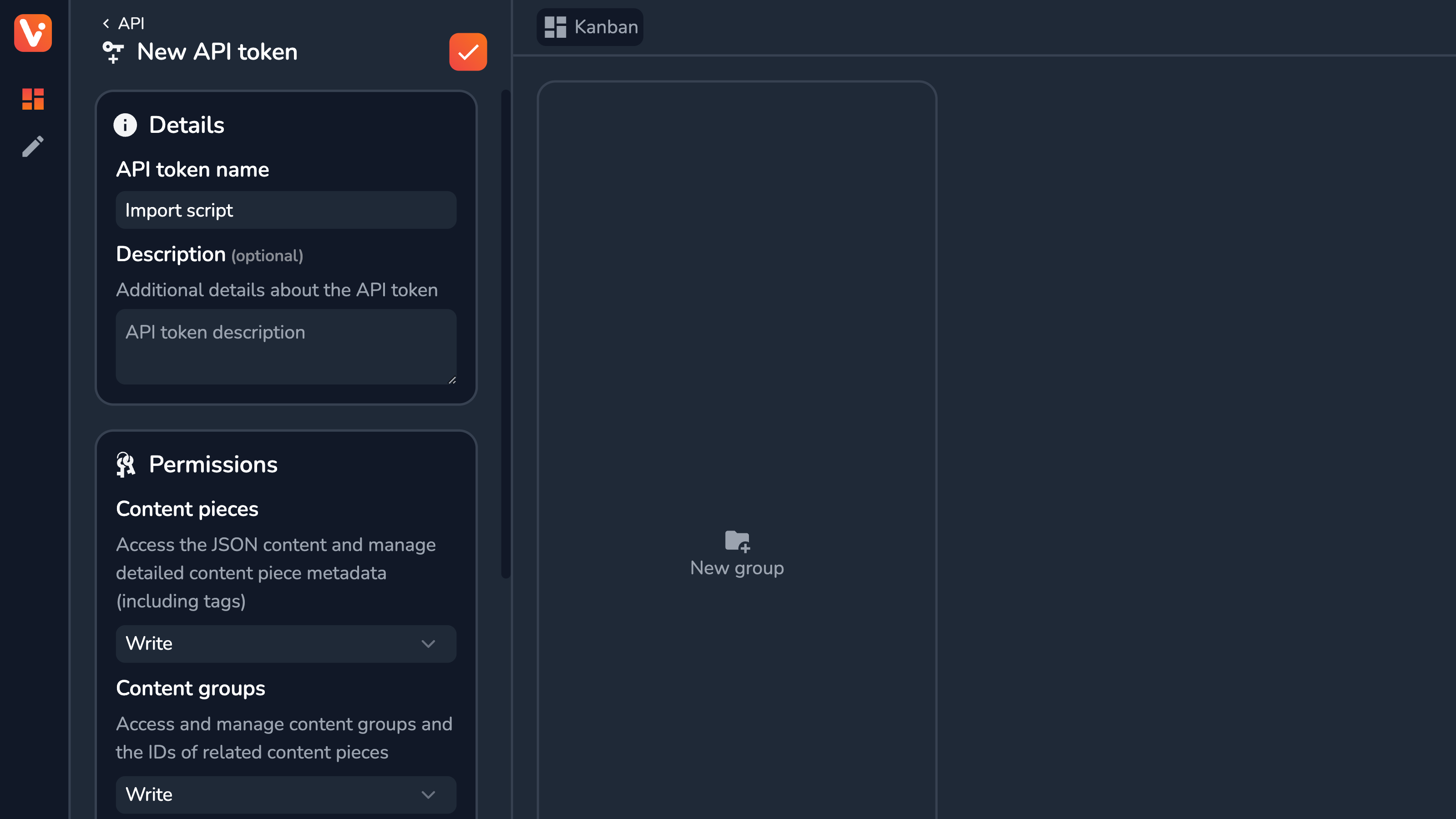
Once you create it, store the token in a safe place - you won’t be able to see it again.
To get an API key from Dev.to, go to the Settings → Extensions → DEV Community API Keys section → provide a description and click Generate API Key.
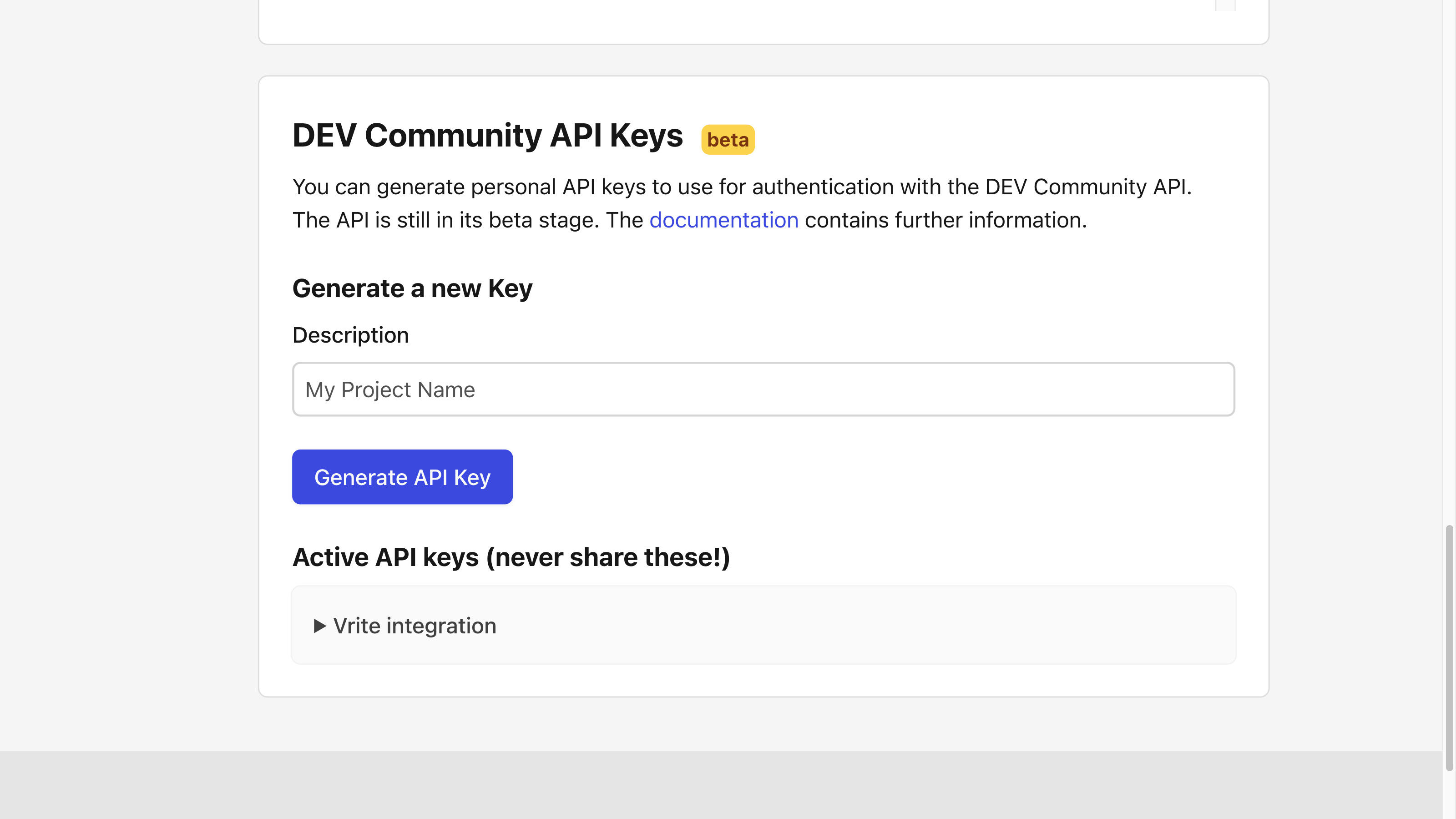
You will be able to see your API Key at any time, though you should still keep it secure.
Importing Content From Dev.to
With API tokens ready, it’s time to prepare an import script.
With Node.js (v18 or newer) and NPM installed, initialize a new project, install Vrite SDK, and create the primary import.mjs file.
npm init -y
npm install @vrite/sdk
touch import.mjsInside import.mjs, let’s first create a function to fetch your articles from Dev.to.
const VRITE_API_TOKEN = "...";
const DEV_API_KEY = "...";
const getDevArticles = async (perPage = 1000) => {
const response = await fetch(
`https://dev.to/api/articles/me/published?per_page=${perPage}`,
{
headers: {
accept: "application/vnd.forem.api-v1+json",
"api-key": DEV_API_KEY,
},
}
);
const data = await response.json();
return data.reverse();
};From v18, Node.js provides a fetch() API, similar to web browsers, which makes handling network requests much easier. Use it with the proper URL and headers to make a request to the User's published articles endpoint.
The Dev.to API implements pagination, with the max value being 1000, so a single request should be enough to retrieve all the articles for most (if not all) users.
To actually import the content to Vrite, let’s create a separate function.
import { createClient } from "@vrite/sdk";
import { gfmInputTransformer } from "@vrite/sdk/transformers";
// ...
const importToVrite = async (numberOfArticles) => {
const articles = await getDevArticles(numberOfArticles);
const client = createClient({
token: VRITE_API_TOKEN,
});
const { id: contentGroupId } = await client.contentGroups.create({
name: "My Dev.to Articles",
});
for await (const article of articles) {
const {
title,
body_markdown,
published_at,
cover_image,
canonical_url,
url,
} = article;
const { content } = gfmInputTransformer(body_markdown);
try {
await client.contentPieces.create({
contentGroupId,
title,
cover_image,
canonicalLink: canonical_url || url,
content,
coverUrl: cover_image,
date: published_at,
members: [],
tags: [],
});
console.log(`Imported article: "${title}"`);
} catch (error) {
console.error(`Could not import article: "${title}"`, error);
}
}
};The .mjs extension in newer versions of Node.js allows out-of-the-box use of ESM import syntax, which we use to import Vrite SDK and gfmInputTransformer.
Vrite SDK provides a few built-in input and output transformers. These are functions, with standardized signatures to process the content from and into Vrite. In this case, gfmInputTransformer is essentially a GitHub Flavored Markdown parser, using Marked.js under the hood.
In the importToVrite() function, we first retrieve articles from DEV using the mechanism discussed before and initialize the Vrite API client. From there, we create a new content group for housing the content and loop over the imported articles using for await to create new content pieces from them.
The created pieces include the transformed content and some additional metadata sourced from Dev.to, to easily identify individual pieces.
With that, all you have to do is call the importToVrite() function with the number of your latest Dev.to articles to import and watch it go! Here’s the entire script:
import { createClient } from "@vrite/sdk";
import { gfmInputTransformer } from "@vrite/sdk/transformers";
const VRITE_API_TOKEN = "...";
const DEV_API_KEY = "...";
const getDevArticles = async (perPage = 1000) => {
const response = await fetch(
`https://dev.to/api/articles/me/published?per_page=${perPage}`,
{
headers: {
accept: "application/vnd.forem.api-v1+json",
"api-key": DEV_API_KEY,
},
}
);
const data = await response.json();
return data.reverse();
};
const importToVrite = async (numberOfArticles) => {
const articles = await getDevArticles(numberOfArticles);
const client = createClient({
token: VRITE_API_TOKEN,
});
const { id: contentGroupId } = await client.contentGroups.create({
name: "My Dev.to Articles",
});
for await (const article of articles) {
const {
title,
body_markdown,
published_at,
cover_image,
canonical_url,
url,
} = article;
const { content } = gfmInputTransformer(body_markdown);
try {
await client.contentPieces.create({
contentGroupId,
title,
cover_image,
canonicalLink: canonical_url || url,
content,
coverUrl: cover_image,
date: published_at,
members: [],
tags: [],
});
console.log(`Imported article: "${title}"`);
} catch (error) {
console.error(`Could not import article: "${title}"`, error);
}
}
};
importToVrite(20);
Search and Q&A in Vrite Dashboard
With the content now in Vrite, let’s go back to the dashboard and see how to use the command palette to search right in Vrite.
When coupled with Vrite support for collaboration, the built-in search and command palette can serve as a great tool when using Vrite as an internal knowledge base.
To open the palette use ⌘K (on macOS), Ctrl K (on Windows or Linux), or the search button in the dashboard’s toolbar.
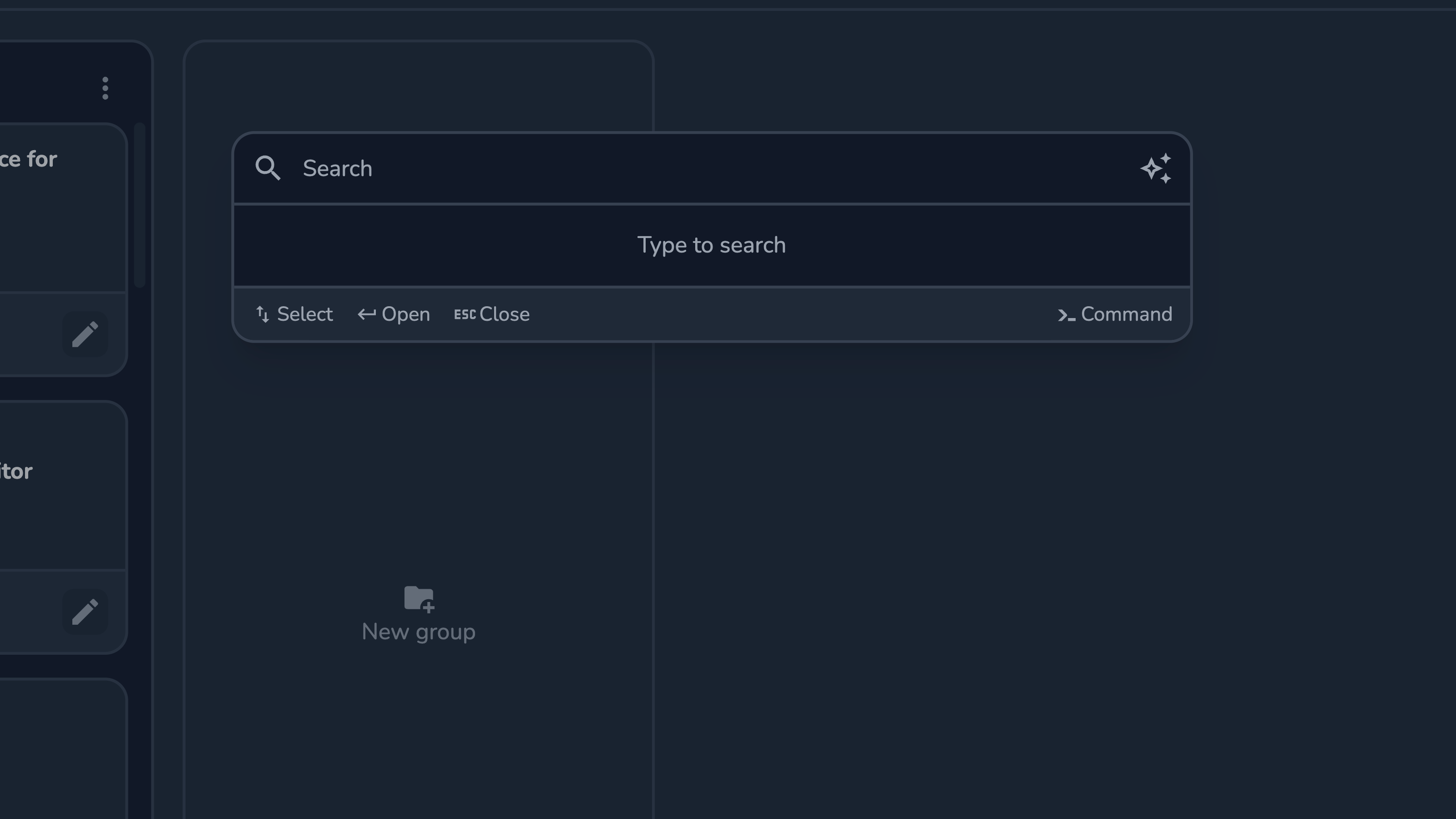
The command palette has 3 modes:
Search — the default, provides results as you type;
Command — can be enabled by typing
>in empty search or by clicking the Command button in the bottom-right corner; Allows quick access to various actions available in the current view; You can move back to the search mode by usingBackspacein empty input;Ask / Q&A — can be enabled by clicking the Ask button in the top-right corner; Type in your question and click
Enterto request an answer;
Try searching for any term and see results from your various Dev.to blog posts appear.
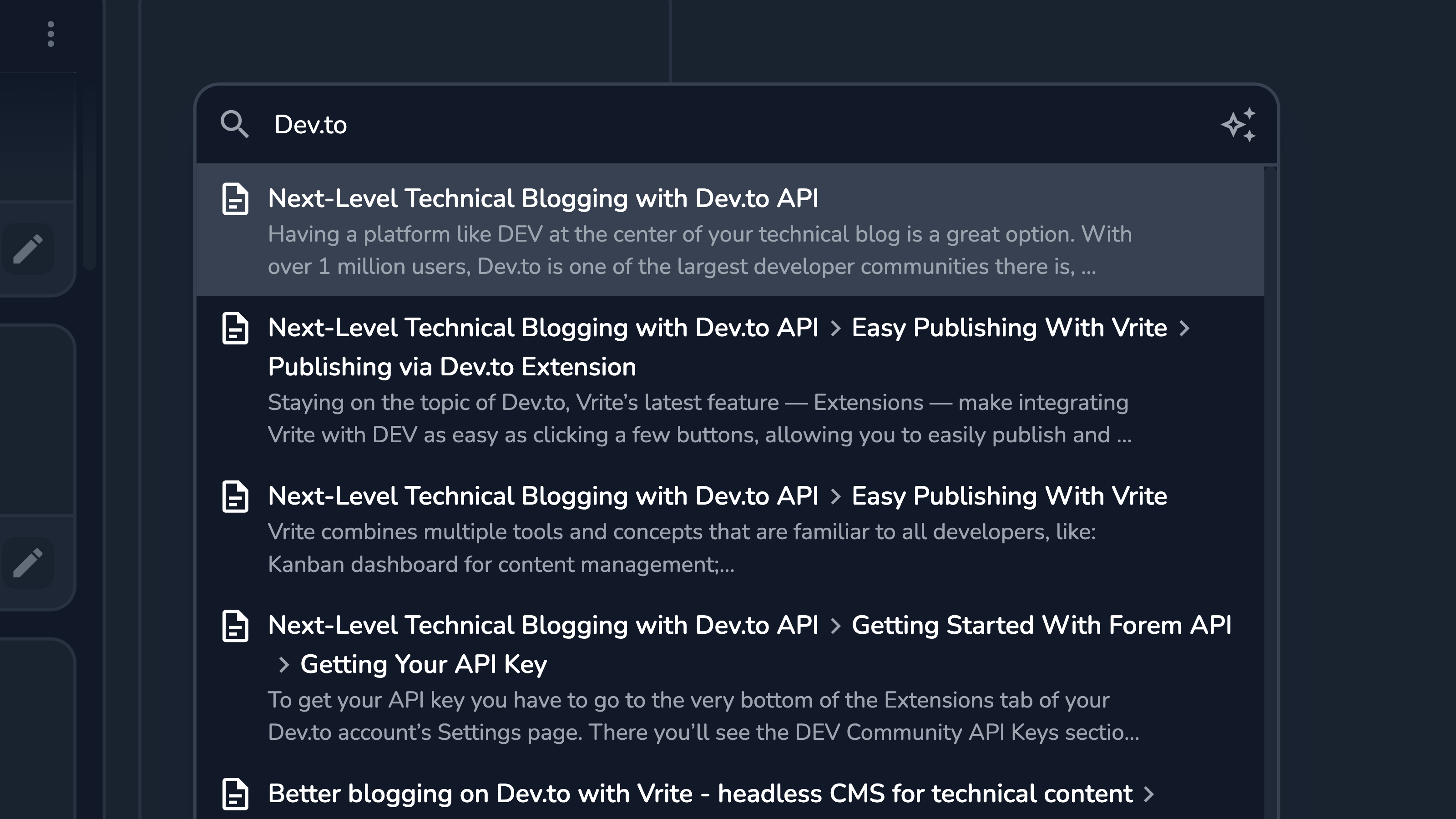
Vrite indexes entire sections of your content pieces, identified by the title and a set of headings. This allows the LLM to extract the most semantic meaning from the content, which enables vector search to provide better search results for your queries. So, the better you structure your posts the better the search results will be.
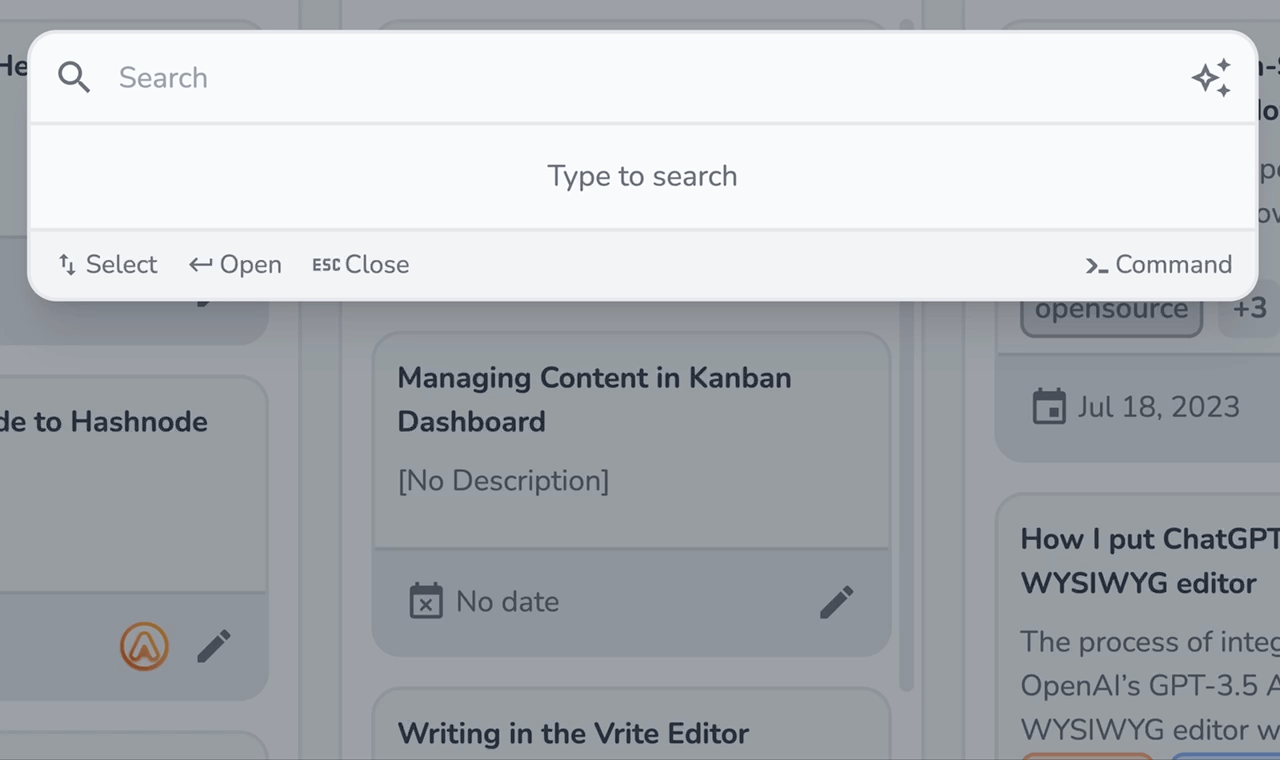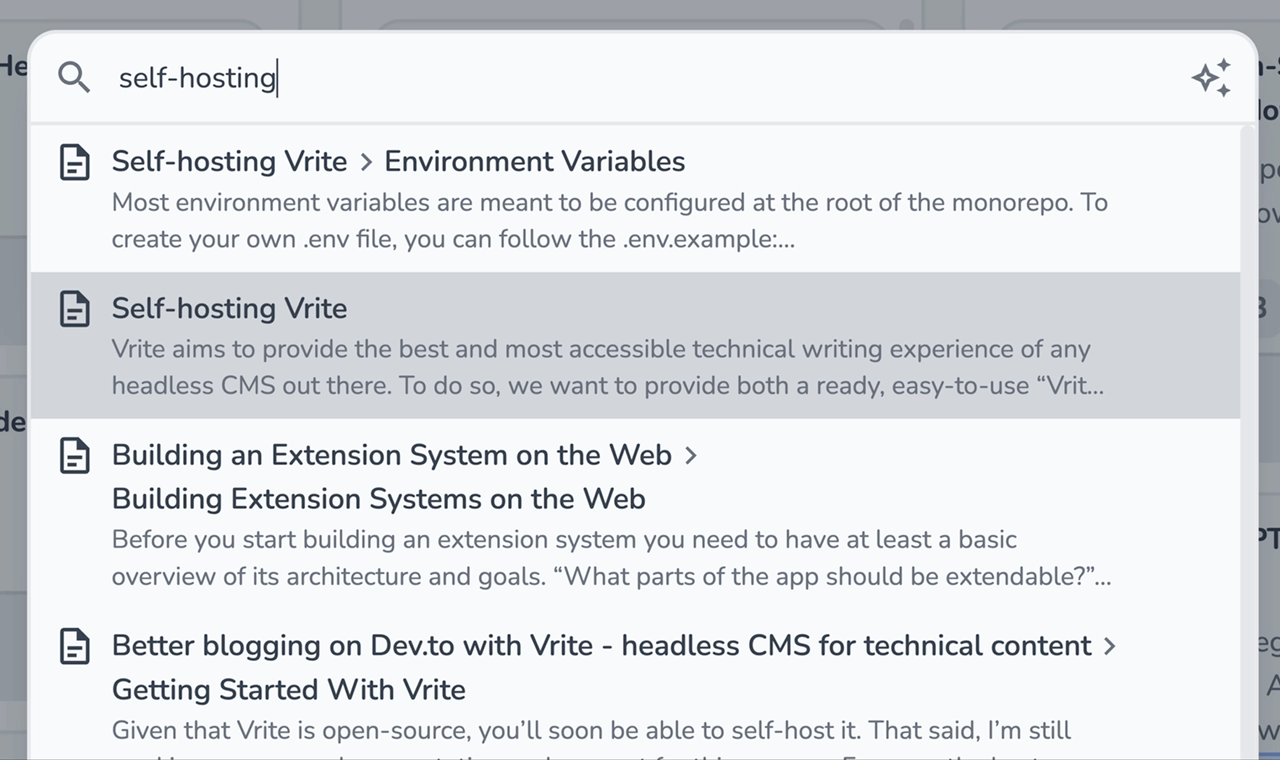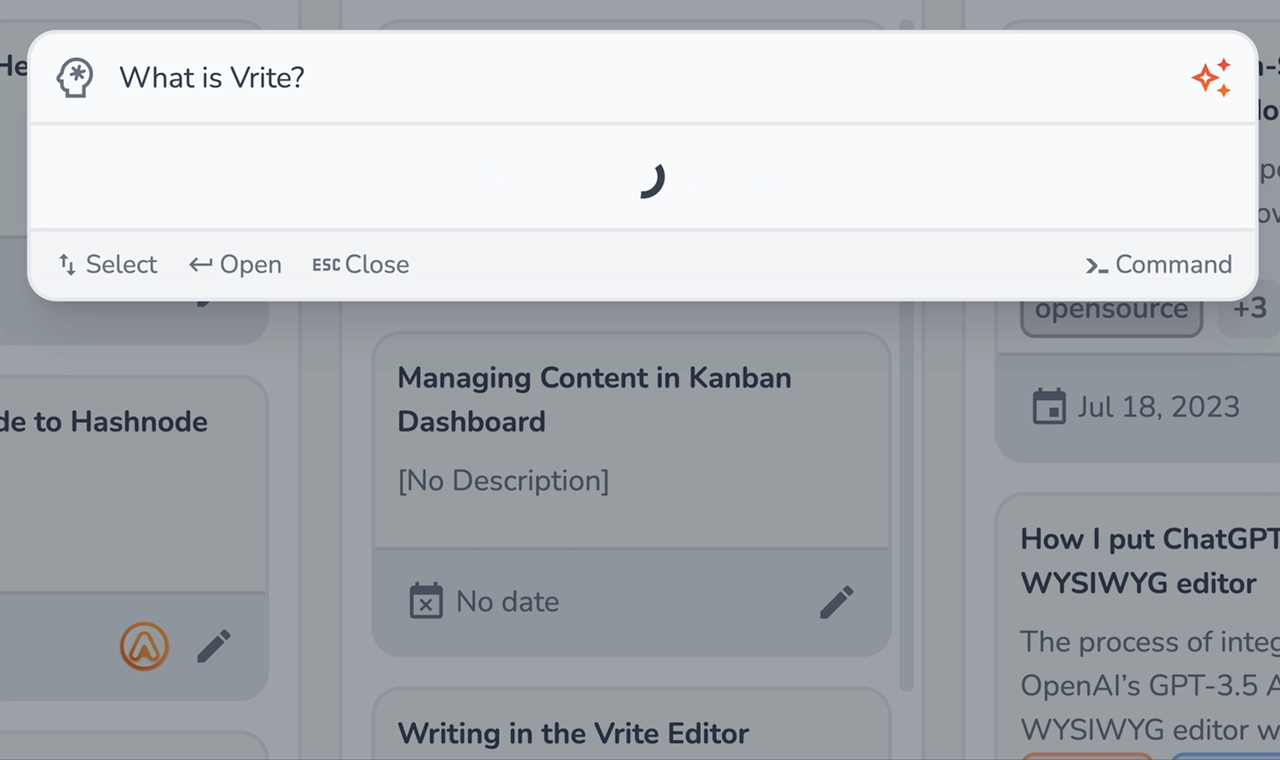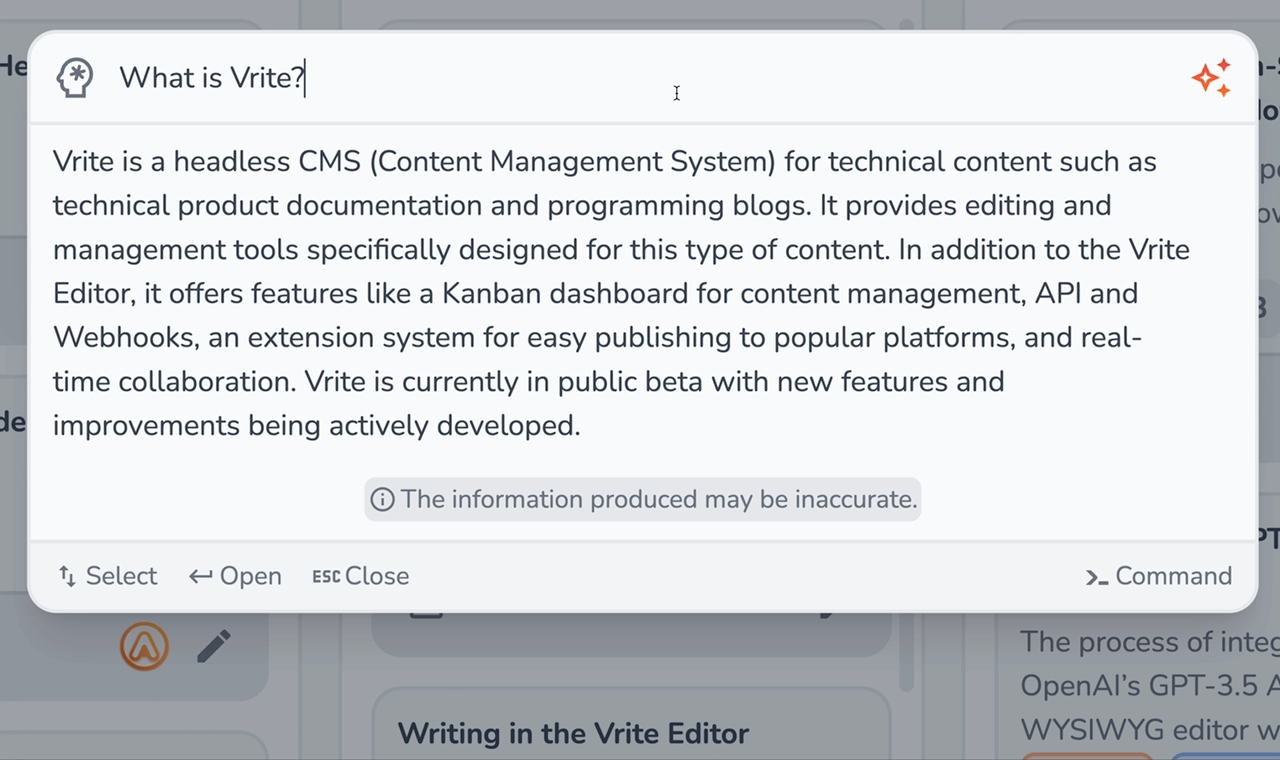
You can also try the Q&A mode, asking any question that there should be an answer for in your content. Upon submission, the prompt is sent together with the context, for GPT-3.5 to generate an answer, which is streamed back to the command palette.
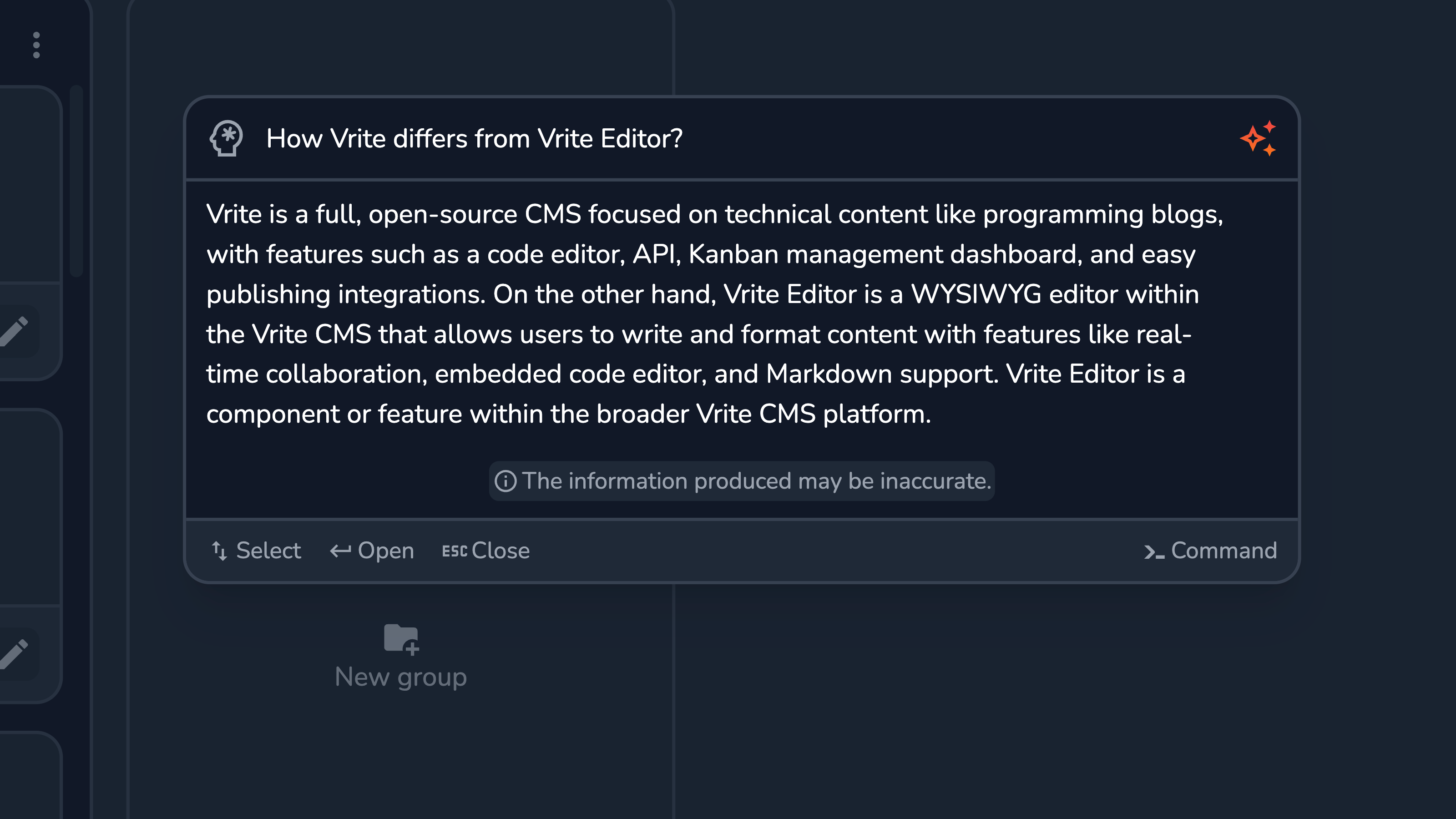
Personally, I was quite impressed with how well the Q&A turned out. Even answers that would require reading through several pieces were generated accurately in seconds. Still, you should keep in mind that this won’t always be the case.
Search and Q&A via Vrite API
Now, searching through Vrite’s command palette is nice, but the real fun begins when you get to implement this search and Q&A experience on your own blogs and docs via Vrite API.
First, you’ll have to “proxy” Vrite API searches via your own backend or serverless functions, due to CORS and security considerations (especially if your token has powerful permissions). To do so, you’ll have to access Vrite API from Node.js.
Search
First, make sure to have an API token with at least Read access to Content pieces. With that, you can use the search() method of the API client to retrieve the results.
import { createClient } from "@vrite/sdk";
const VRITE_API_TOKEN = "...";
const search = async (query) => {
const client = createClient({
token: VRITE_API_TOKEN,
});
const results = await client.search({ query });
console.log(results);
};
search("Dev.to");The search result is an array of objects, each containing:
contentPieceId— ID of the related content piece;breadcrumb— an array of the title and headings leading to the section;content— plain text content of the section;
You can process or send these results directly to the frontend as a JSON array.
Q&A
Q&A is a bit more difficult. Due to the slow response associated with the time GPT-3.5 needs to generate an answer, the /search/ask endpoint is implemented via Server Sent Events (SSEs) to stream the answer to the user, allowing them to see the first tokens as soon as they’re ready.
Vrite SDK doesn’t support SSE streaming just yet, so, for now, you’ll have to implement this yourself. Use the eventsource library or similar to connect with the endpoint and stream the answer.
const streamAnswer = async (query) => {
try {
const source = new EventSource(
`https://api.vrite.io/search/ask?query=${encodeURIComponent(query)}`,
{
headers: { Authorization: `Bearer ${VRITE_API_TOKEN}` },
}
);
let content = "";
return new Promise((resolve, reject) => {
source.addEventListener("error", (event) => {
if (event.message) {
return reject(event.message);
} else {
source.close();
return resolve(content);
}
});
source.addEventListener("message", (event) => {
content += decodeURIComponent(event.data);
});
});
} catch (error) {
console.log(error);
}
};
streamAnswer("What is Dev.to?").then((answer) => {
console.log(answer);
});The example loads the entire answer and then resolves the Promise. You can use this method directly, but the response time for each request will be counted in seconds.
To provide a better User Experience (UX), you’ll likely want to forward the events coming from Vrite API, through your backend to the frontend, where the user will see the first tokens of the answer appear much faster. The implementation of this will depend on your backend framework, but the general approach is to write a text/event-stream response as the data comes in. Here’s a good overview of the general process.
I’m working to document and support this process better in the coming weeks.
Bottom Line
While the AI search itself is really great, the best part about Vrite is that the search is only a small fraction of a greater whole. With the Kanban content management, WYSIWYG technical content editor, Git sync, and extensions for publishing to platforms like Dev.to with just drag and drop — we’ve only scratched the surface of what’s possible!
Now, Vrite is currently in Beta and there are still bugs to be resolved, and new features to be added and fleshed out. If you want to help and support the project, leave a star on GitHub and report any issues or bugs you encounter. With your support, I hope to make Vrite the go-to, open-source technical content platform 🔥